Technical Specifications
Lingotek XLIFF 2.0 Filter Configuration Options
Allows user to control filters (config file for filter).
xxx.
Enhancements
- If a unit has canResegment="yes" and the config option needsSegmentation.b=true is set, linguistic segmentation is applied to the content as if it were a paragraph. XLIFF 2.0 assumes all unit content is pre-segmented and are sentences. Generally XLIFF 2.0 segmentation can be changed (split/merge for example) but there is no specific option in the standard to mark the content as a paragraph. For more information, click here.
- The config option simplifyTags.b=true directs the system to not simplify inline codes. Otherwise ending and trailing codes are trimmed and any consecutive codes are merged to simplify the presentation to the translator.
- The config option mergeAsParagraph.b=true directs the system to forget any segmentation applied with needsSegmentation.b=true and merges the unit as one, single segment. This option is useful when the original segmentation is needed, not the segmentation introduced by Lingotek.
- The config option useCodeFinder.b=true allows regular expression based rules to be written that convert text into inline codes and protects these codes from translation in the workbench. For example, emoji substrings can be supported using custom codefinder rules. On merge the XLIFF wrapper elements are removed and only the original (protected) content remains.
- The option maxValidation.b=true enables stricter XLIFF 2.0 schema checking and reports errors to the user assuring compliant files.
For highly technical or creative content (where a degree of transcreation is needed), it may be desirable to segment on a paragraph (rather than a sentence). We’ve added the ability to turn segmentation on or off for XLIFF 2.0 files via the FPRM filter. Additionally, we’ve added the option to turn segmentation on/off for a specific unit ID.
To segment a document by something other than the XLIFF 2.0 defaults,
- Enable paragraph segmentation within the FPRM filter.
- Enable paragraph segmentation within the document. This can be controlled via each unit within the document.
Set the FPRM Filter
Adjust Segmentation (via the FPRM Filter Config)
By default, Lingotek's XLIFF 2.0 filter configuration segments documents into sentences. To adjust segmentation, use the following variables (mergeAsParagraph, needsSegmentation) in the FPRM filter config file (defined and outlined below).
A bilingual XLIFF 2.0 file CANNOT have the filter config set to needsSegmentation.b="true" (this will cause it to error out).
Can't segment on both source and target paragraphs
if transl. is already segmented into paragraphs...
mergeAsParagraph.b
In the filter config, use mergeAsParagraph.b to specify how segments will be treated when the file is downloaded again.
- True: The file will be merged back with its original segmentation.
- False: The file will be merged back with the new segmentation specified by Lingotek.
needsSegmentation.b
In the filter config, use needsSegmentation.b to determine whether segmentation can be adjusted on the XLIFF 2.0 file. (XLIFF by nature already has the segments/text units defined. The default behavior in the XLIFF 2 filter is to NOT resegment).
- True: Further segmentation can be enabled on the XLIFF file.
- False: Further segmentation is not enabled on the XLIFF file.
![]() A bilingual XLIFF CANNOT have the filter config set to needsSegmentation.b="true" (this will cause it to error out).
A bilingual XLIFF CANNOT have the filter config set to needsSegmentation.b="true" (this will cause it to error out).
Choose to segment by paragraph, sentence, or phrase.
Use the instructions below to adjust the FPRM filter config.
![]() Tip: When uploading a document needing custom segmentation, apply the newly created FPRM filter config.
Tip: When uploading a document needing custom segmentation, apply the newly created FPRM filter config.
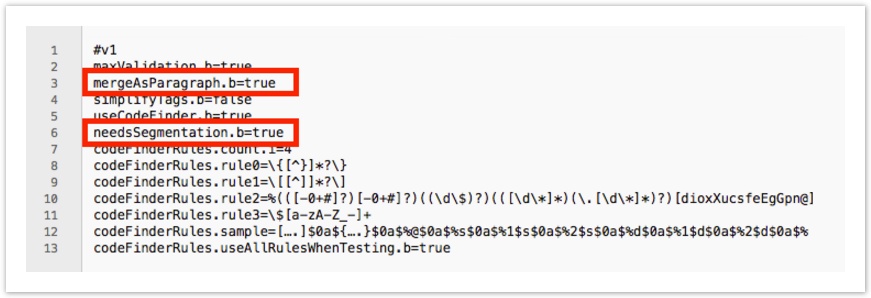
- To segment on paragraphs, add:
- mergeAsParagraph.b=true
- needsSegmentation.b=true
- To segment on sentences, leave the FPRM filter's default settings.
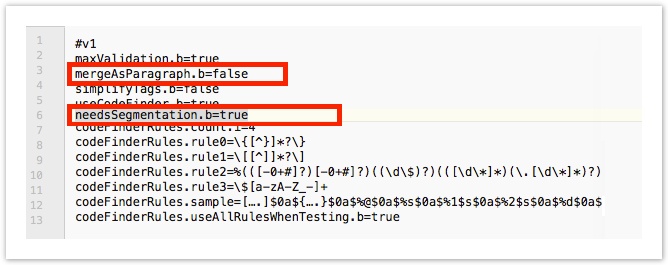
- To segment on phrases (i.e. something shorter than a sentence), add:
- mergeAsParagraph.b=false
- needsSegmentation=true
Set the Document
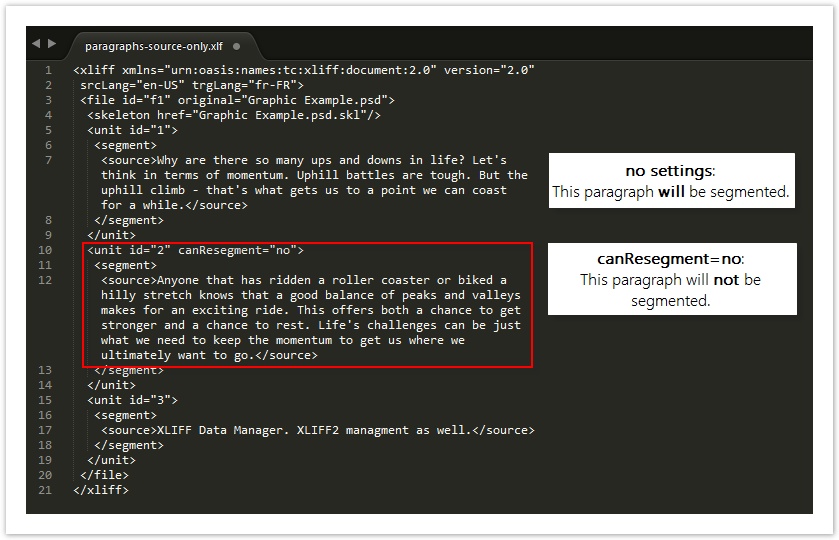
After applying the appropriate FPRM filter, go into the XLIFF 2.0 document and adjust its segmentation. By default, the file will segment on sentences. If there is a paragraph that should not be segmented (i.e. its contents should be a single segment), you can set the canResegment variable.
canResegment
To combine all sentences within a unit into a single segment, go into the unit and set canResegment=no. This will bundle the entire paragraph into a single segment.