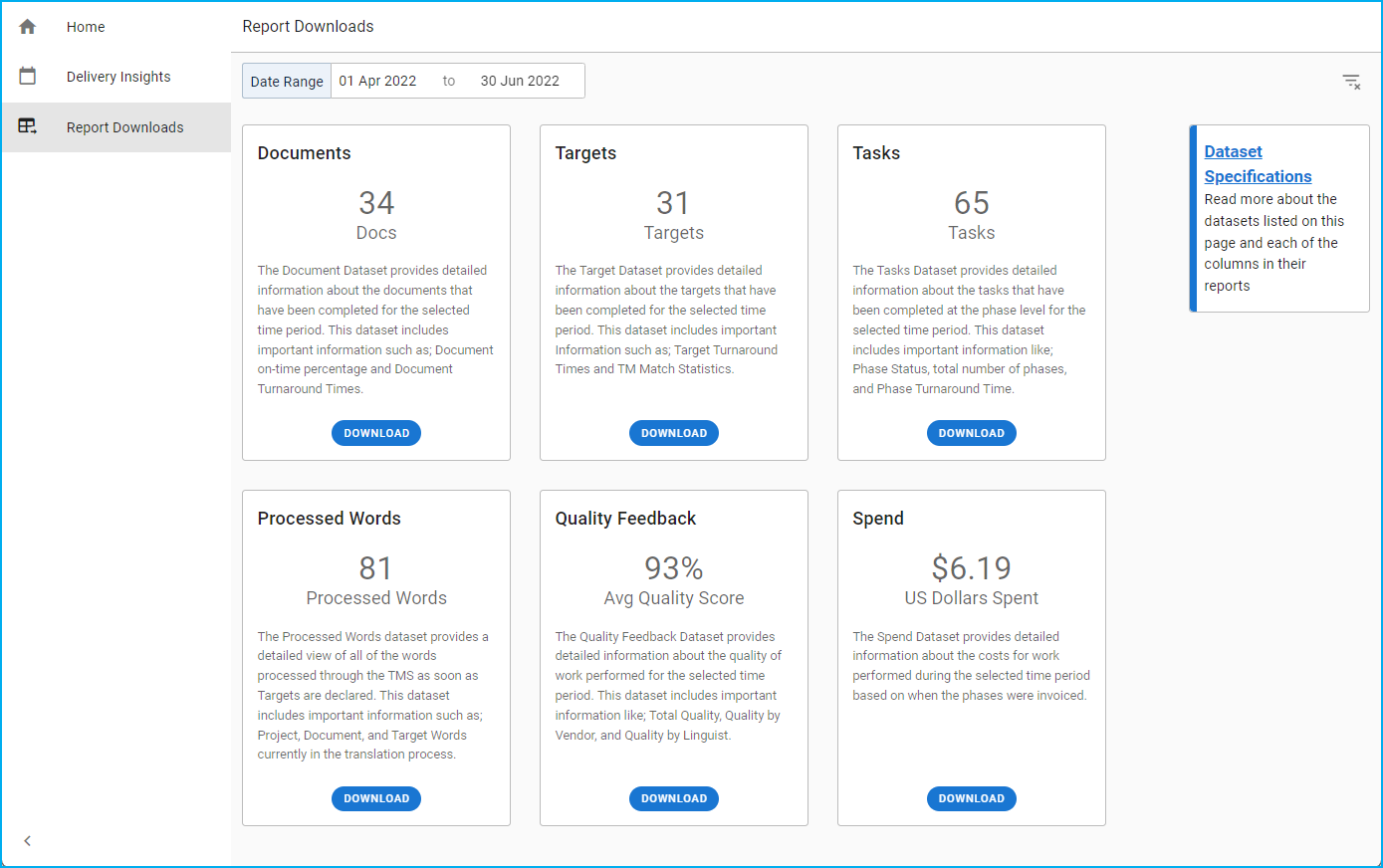
Column Name | Data Type | Description |
|---|
community_uid | String (UUID) | Community UUID |
community_name | String | Community Name |
community_id | String | Legacy community ID |
project_uid | String (UUID) | Project UUID |
project_name | String | Project name |
project_due_time | Timestamp | Due date set for the project |
project_quality_program_id | String (UUID) | The ID of the quality program used for all content in the project |
project_created_at | Timestamp | The date the project was created |
document_uid | String (UUID) | Document UUID |
document_name | String | Document Name |
document_locale | String | The locale of the source document |
document_language_description | String | The language the language code represents (EX: "English") |
document_country_description | String | The country the locale code represents (EX: "United States") |
document_note | String | A note left on the document used to provide useful information and instructions |
document_requested_document_format | String | The source format code in the Lingotek system |
document_duplicate_segment_count | Integer | The number of segments that are repeated in the document. |
document_unique_segment_count | Integer | The number of unique segments in the document. |
document_requested_importer_version | String | The importer version used to import the source file into the TMS |
document_format_tag_count | Integer | The number of format tags found on the source file after the filtering and import process. |
document_unique_word_count | Integer | The number of unique words in the source file. |
document_translation_units | Integer | The number of segments in the document. |
document_start_date | Timestamp | The date the document was 'ready' for translation. |
document_character_count | Integer | The number of characters on the source file. |
document_upload_date | Timestamp | The date the document was uploaded to the TMS. |
document_duplicate_word_count | Integer | The number of duplicated words in the source file. |
document_percent_complete | Integer | The percent progress of the document. |
document_source_word_count | Integer | The total word count of the source document. |
document_weighted_word_count | Integer | The sum the document's targets' weighted word counts. |
document_save_to_vault | String | The vault that created translation memory will be saved to unless otherwise specified at the target level |
document_next_document_uuid | String (UUID) | The document version created when this document was updated |
document_prev_document_uuid | String (UUID) | The document version this document was updated from |
document_parent_document_uuid | String (UUID) | The original document uploaded to the TMS that this and all other document versions were created from. |
document_format_code | String | The format code of the source document's file type |
document_format_name | String | The description of the document_format_code |
document_importer_version_code | String | The code of the importer version |
document_author_name | String | Document metadata |
document_external_style_id | String | Document metadata |
document_creation_user | String | Document metadata |
document_channel | String | Document metadata |
document_external_document_id | String | Document metadata |
document_reference_url | String | Document metadata |
document_complete_date | String | The date the document was completed |
document_external_application_id | String | Document metadata |
document_contact_email | String | Document metadata |
document_campaign_rating | Decimal | Document metadata |
document_content_type | String | Document metadata |
document_author_email | String | Document metadata |
document_campaign_id | Integer | Document metadata |
document_require_review | Boolean | Document metadata |
document_contact_name | String | Document metadata |
document_domain_type | String | Document metadata |
document_company_id | Integer | Document metadata |
document_original_due_date | Timestamp | The due date first set on the document |
document_due_date | Timestamp | The current due date set on the document |
document_original_due_reason | Integer | The reason the original due date was changed |
document_due_reason | Integer | The reason the document's due date was changed to the current due date |
document_application_name | String | The name of the application that uploaded the document to the Lingotek TMS |
document_business_unit | String | Document metadata |
document_content_description | String | Document metadata |
document_business_division | String | Document metadata |
document_purchase_order | String | Document metadata |
document_job_id | String | Document metadata |
document_region | String | Document metadata |
document_priority_name | String | Document metadata |
document_company_name | String | Document metadata |
document_company_uid | String (UUID) | Document metadata |
document_status | String | The document status when it was completed. The status will be "complete", "late", or "cancelled" |
document_status_description | String | The definition of the document_status |
document_status_reason | String | The reason for the document's status. Generally supplied when the document is late or cancelled. |
document_status_reason_description | String | The user facing version of the document_status_reason |
document_cancelled_at | Timestamp | The time the document was cancelled |
document_created_at | Timestamp | The time the document was created |
document_modified_at | Timestamp | The time the document was updated to a new version |
target_uid | String (UUID) | The target UUID |
target_locale | String | The locale the source document is being translated to |
target_language_description | String | The language the language code represents (EX: "German") |
target_country_description | String | The country the locale code represents (EX: "Germany") |
target_fast_track_eligible | Boolean | The total word count of the target equals the exact match word count. |
target_start_date | Timestamp | The date the target is set to ready |
target_complete_date | Timestamp | The date the target was marked complete |
target_weighted_word_count | Integer | The target weighted word count |
target_status | String | The target status when it was completed. The status will always be complete, late, or cancelled |
target_status_description | String | The definition of the target_status |
target_status_reason | String | The reason for the target's status. Generally supplied when the target is late or cancelled. |
target_status_reason_description | String | The user facing version of the target_status_reason |
target_due_date | Timestamp | The target due date |
target_due_reason | String | The reason the target due date was changed |
target_due_reason_description | String | The user-facing version of the target_due_reason |
target_cancelled_at | Timestamp | The time the target was cancelled |
target_created_at | Timestamp | The time the target was created |
target_modified_at | Timestamp | The last time a target was changed |
target_quality_actual_error_points | Decimal | The actual number of error points a target is docked according to scorecards/severities |
target_quality_normalized_error_points | Decimal | This represents the value of how many error points can be allowed before a target has a failing quality score given an expected word count per target. |
target_quality_actual_quality_score | Decimal | This is also called the "Quality Score" in the quality reports. This represents the score that must be beaten for a target to pass |
target_quality_pass_fail_status | String | This field states whether a document has passed or failed and is based on the error points calculated from scorecards/severities |
target_quality_threshold_wc | Integer | This is also called the "Standard Word Count" in the quality report, and is used to normalize the actual error points found from feedback entries. This value represents an expected word count per target and then normalizes based on the targets actual word count. |
target_quality_threshold_allowance | Integer | This represents how many error points can be allowed according to the quality program's passing score. If a quality program's passing score is 71, then the threshold allowance is 29 (100 - 71) |
target_quality_threshold_type | String | Whether the error threshold should be weighed points (per how many words) or total points |
target_quality_threshold_allowance_points | Integer | How many "bad" points a quality score has before it's not considered, i. e. 10 points and you're out |
target_quality_threshold_allowance_percentage | Decimal | A "bad" percentage a quality score has before it's not considered, i. e. 10% and you're out "thresholdAllowancePoints / thresholdWc) * 100)" |
target_quality_minimum_quality_score | Decimal | The most minimum a score can be to be considered, "100 - thresholdAllowancePercentage" |
target_quality_created_at | Timestamp | When the quality score was created for a document, a timestamp |
leverage_id | String (UUID) | The ID of the leverage report run on the first leverage phase on the target, if there wasn't a leverage report, then this field as well as the other analysis fields will be blank even if leverage reports are run manually. |
leverage_name | String | The name given to the leverage report |
source_leverage_character_count | Integer | The number of characters in the analyzed source file |
source_leverage_word_count | Integer | The number of words in the analyzed source file |
source_leverage_segment_count | Integer | The number of segments in the analyzed source file |
source_leverage_format_tag_count | Integer | The number of tags in the analyzed source file |
source_leverage_segment_repetition_total | Integer | The number of segments that are repeated in the analyzed source file |
source_leverage_segment_repetition_unique | Integer | The number of unique segments in the analyzed source file |
source_leverage_segment_repetition_total_words | Integer | The number of repeated words in the analyzed source file |
source_leverage_segment_repetition_unique_words | Integer | The number of unique words in the analyzed source file |
target_leverage_ignore_locale | Boolean | A leverage setting that controls if the locale of both the source and target are ignored in the leverage process. |
tm_match_translated_segment_count | Integer | The number of segments found in the analysis that were already filled with translations |
tm_match_repetitions_segment_count | Integer | The number of repeated segments found in the analysis |
tm_match_exact_100_segment_count | Integer | The number of segments that found an Exact 100% match with a TM unit in the leveraged vault |
tm_match_syntax_100_segment_count | Integer | The number of segments that found an Syntax 100% match with a TM unit in the leveraged vault |
tm_match_99_95_segment_count | Integer | The number of segments that found a match between 99% and 95% in the leveraged vault |
tm_match_94_85_segment_count | Integer | The number of segments that found a match between 94% and 85% in the leveraged vault |
tm_match_84_75_segment_count | Integer | The number of segments that found a match between 84% and 75% in the leveraged vault |
tm_match_74_50_segment_count | Integer | The number of segments that found a match between 74% and 50% in the leveraged vault |
tm_match_49_0_segment_count | Integer | The number of segments that found a match between 49% and 0% in the leveraged vault. These are not considered significant matches. |
tm_match_total_segment_count | Integer | The total number of segments found in the analysis |
tm_match_translated_word_count | Integer | The number of words that were part of already translated segments |
tm_match_repetitions_word_count | Integer | The number of words found in repeated segments |
tm_match_exact_100_word_count | Integer | The number of words in segments that found an Exact 100% match with a TM unit in the leveraged vault |
tm_match_syntax_100_word_count | Integer | The number of words in segments that found an Syntax 100% match with a TM unit in the leveraged vault |
tm_match_99_95_word_count | Integer | The number of words in segments that found a match between 99% and 95% in the leveraged vault |
tm_match_94_85_word_count | Integer | The number of words in segments that found a match between 94% and 85% in the leveraged vault |
tm_match_84_75_word_count | Integer | The number of words in segments that found a match between 84% and 75% in the leveraged vault |
tm_match_74_50_word_count | Integer | The number of words in segments that found a match between 74% and 50% in the leveraged vault |
tm_match_49_0_word_count | Integer | The number of words in segments that found a match between 49% and 0% in the leveraged vault. These are not considered significant matches. |
tm_match_total_word_count | Integer | The total number of words found in the analysis |
tm_match_translated_wwc | Integer | The weighted word count calculated for words in already translated segments |
tm_match_repetitions_wwc | Integer | The weighted word count calculated for repeated segments |
tm_match_exact_100_wwc | Integer | The weighted word count calculated for Exact 100% matches |
tm_match_syntax_100_wwc | Integer | The weighted word count calculated for Syntax 100% matches |
tm_match_99_95_wwc | Integer | The weighted word count calculated for 99%-95% matches |
tm_match_94_85_wwc | Integer | The weighted word count calculated for 94%-85% matches |
tm_match_84_75_wwc | Integer | The weighted word count calculated for 84%-75% matches |
tm_match_74_50_wwc | Integer | The weighted word count calculated for 74%-50% matches |
tm_match_49_0_wwc | Integer | The weighted word count calculated for 49%-0% matches |
tm_match_total_wwc | Integer | The sum of the calculated weighted word counts across all match types |
tm_match_translated_tag_count | Integer | The number of tags that were part of already translated segments |
tm_match_exact_100_tag_count | Integer | The number of tags in segments that found an Exact 100% match with a TM unit in the leveraged vault |
tm_match_syntax_100_tag_count | Integer | The number of tags in segments that found an Syntax 100% match with a TM unit in the leveraged vault |
tm_match_99_95_tag_count | Integer | The number of tags in segments that found a match between 99% and 95% in the leveraged vault |
tm_match_94_85_tag_count | Integer | The number of tags in segments that found a match between 94% and 85% in the leveraged vault |
tm_match_84_75_tag_count | Integer | The number of tags in segments that found a match between 84% and 75% in the leveraged vault |
tm_match_74_50_tag_count | Integer | The number of tags in segments that found a match between 74% and 50% in the leveraged vault |
tm_match_49_0_tag_count | Integer | The number of tags in segments that found a match between 49% and 0% in the leveraged vault. These are not considered significant matches. |
tm_match_total_tag_count | Integer | The total number of tags found in the analysis |
tm_leveraged_exact_100_segment_count | Integer | The number of segments that found a 100% Exact match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_syntax_100_segment_count | Integer | The number of segments that found a 100% Syntax match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_99_95_segment_count | Integer | The number of segments that found a 99% - 95% match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_94_85_segment_count | Integer | The number of segments that found a 94% - 85% match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_84_75_segment_count | Integer | The number of segments that found a 84% - 75% match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_74_50_segment_count | Integer | The number of segments that found a 74% - 50% match that was leveraged (or saved as a translation) into the segment. |
tm_under_leverage_minimum_segment_count | Integer | All the segments that matched below the mimimum threshold in the settings. |
tm_leveraged_total_segment_count | Integer | The total number of segments that were leveraged (or saved as a translation) in the target |
tm_leveraged_exact_100_word_count | Integer | The number of words in segments that found a 100% Exact match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_syntax_100_word_count | Integer | The number of words in segments that found a 100% Syntax match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_99_95_word_count | Integer | The number of words in segments that found a 99% - 95% match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_94_85_word_count | Integer | The number of words in segments that found a 94% - 85% match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_84_75_word_count | Integer | The number of words in segments that found a 84% - 75% match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_74_50_word_count | Integer | The number of words in segments that found a 74% - 50% match that was leveraged (or saved as a translation) into the segment. |
tm_under_leverage_minimum_word_count | Integer | All the words in segments that matched below the mimimum threshold in the settings. |
tm_leveraged_total_word_count | Integer | The total number of words in segments that were leveraged (or saved as a translation) in the target |
tm_leveraged_exact_100_tag_count | Integer | The number of tags in segments that found a 100% Exact match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_syntax_100_tag_count | Integer | The number of tags in segments that found a 100% Syntax match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_99_95_tag_count | Integer | The number of tags in segments that found a 99% - 95% match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_94_85_tag_count | Integer | The number of tags in segments that found a 94% - 85% match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_84_75_tag_count | Integer | The number of tags in segments that found a 84% - 75% match that was leveraged (or saved as a translation) into the segment. |
tm_leveraged_74_50_tag_count | Integer | The number of tags in segments that found a 74% - 50% match that was leveraged (or saved as a translation) into the segment. |
tm_under_leverage_minimum_tag_count | Integer | All the tags in segments that matched below the mimimum threshold in the settings. |
tm_leveraged_total_tag_count | Integer | The total number of tags in segments that were leveraged (or saved as a translation) in the target |
target_turnaround_time_hours | Integer | The hours between the target start date to its completion date |
target_finalized_timestamp | Timestamp | The time the target was finalized, and eligible to be added in the intelligence database. Targets are finalized when they enter a completed status. |
target_finalized_date | Date | The calendar date the target was finalized |
target_finalized_year | Integer | The calendar year the target was finalized |
target_finalized_month | Integer | The calendar month the target was finalized |
target_finalized_day | Integer | The day in the calendar year the target was finalized |
target_finalized_week_number | Integer | The week of the year the target was finalized |
target_finalized_start_of_week_mon | Date | The start of the week if this user's organization considers Monday to be the first day of the week. |
target_finalized_start_of_week_sun | Date | The start of the week if this user's organization considers Sunday to be the first day of the week. |
target_finalized_start_of_week_sat | Date | The start of the week if this user's organization considers Saturday to be the first day of the week. |
target_finalized_status | String | The status of the target when it is finalized |